
Depth estimation for corn plant images based on hybrid group dilated convolution
-
摘要:目的
研究面向玉米田间场景的图像深度估计方法,解决深度估计模型因缺少有效光度损失度量而易产生的精度不足问题,为田间智能农业机械视觉系统设计及导航避障等提供技术支持。
方法应用双目相机作为视觉传感器,提出一种基于混合分组扩张卷积的无监督场景深度估计模型。设计一种混合分组扩张卷积结构及对应的自注意力机制,由此构建反向残差模块和深度估计骨干网络;并将光照不敏感的图像梯度和Gabor纹理特征引入视图表观差异度量,构建模型优化目标。以田间玉米植株图像深度估计为例,开展模型的训练和测试试验。
结果与固定扩张因子相比,采用混合分组扩张卷积使田间玉米植株深度估计平均相对误差降低了63.9%,平均绝对误差和均方根误差则分别降低32.3%和10.2%,模型精度显著提高;图像梯度、Gabor纹理特征和自注意力机制的引入,使田间玉米植株深度估计平均绝对误差和均方根误差进一步降低3.2%和4.6%。增加浅层编码器的网络宽度和深度可显著提高模型深度估计精度,但该处理对深层编码器的作用不明显。该研究设计的自注意力机制对编码器浅层反向残差模块中不同扩张因子的卷积分组体现出选择性,说明该机制具有自主调节感受野的能力。与Monodepth2相比,该研究模型田间玉米植株深度估计的平均相对误差降低48.2%,平均绝对误差降低17.1%;在20 m采样范围内,估计深度的平均绝对误差小于16 cm,计算速度为14.3帧/s。
结论基于混合分组扩张卷积的图像深度估计模型优于现有方法,有效提升了深度估计的精度,能够满足田间玉米植株图像的深度估计要求。
Abstract:ObjectiveTo study the image depth estimation methods for corn field scenes, solve the problem of insufficient accuracy in depth estimation models due to the lack of effective photometric loss measures, and provide technical support for the vision system design of field intelligent agricultural machinery and navigation obstacle avoidance.
MethodThis study applied binocular cameras as visual sensors, and proposed an unsupervised depth estimation model based on hybrid grouping extended convolution. A hybrid grouping extended convolution structure and its corresponding self-attention regulation mechanism were designed. The reverse residual module and deep neural network were constructed as the backbone of the model. The illumination insensitive image gradient and Gabor texture features were introduced into the apparent difference measurement of view, and the model optimization objective was constructed based on them. Taking maize plant image as an example, the model training and verification tests were carried out.
ResultCompared with the fixed expansion factor, the average relative error of maize plant depth estimation in the field was reduced by 63.9%, the average absolute error and root mean square error were reduced by 32.3% and 10.2% respectively, and the accuracy of the model was significantly improved. With the introduction of image gradient, Gabor texture feature and self-attention mechanism, the mean absolute error and root mean square error of field scene depth estimation were further reduced by 3.2% and 4.6% respectively. Increasing the network width and depth of shallow encoder could significantly improve the accuracy of model depth estimation, but the effect of this treatment on deep encoder was not obvious. The self-attention mechanism designed in this study was selective to the convolution grouping of different expansion factors in the shallow reverse residual module of the encoder, indicating that the mechanism had the ability to adjust the receptive field. Compared with Monodepth2, the average relative error and the average absolute error of the estimated depth of maize plants in the field of the research model were reduced by 48.2% and 17.1% respectively. Within the sampling range of 20 m, the average absolute error of the estimated depth was no more than 16 cm, and the calculation speed was 14.3 frames per second.
ConclusionThe image depth estimation model based on hybrid group dilated convolution is superior to existing methods, effectively improves the accuracy of depth estimation and can meet the depth estimation requirements of field corn plant images.
-
Keywords:
- Depth estimation /
- Dilated convolution /
- Self-attention /
- Unsupervised learning /
- Corn plant image
-
精准农业是推动农业现代化与信息化发展的关键,其重要的农情数据采集阶段离不开农业物联网(Internet of things in agriculture)的支持[1]。现阶段,农业物联网已在农业生产中得到广泛应用,复杂的传感器网络按时间序列连续地采集温度、湿度、CO2和NH3浓度等大量的环境及作物生长信息。分析和评估采集的信息可为农业精准决策提供保障。因此,农业物联网数据的有效挖掘和利用已成为农业信息化领域的研究热点[2-3]。然而,由于农业作业环境往往较为恶劣,且受制造工艺和网络传输的限制,导致采集到的数据中不可避免地存在异常[4],这些异常可能干扰数据分析并影响农业精准决策。
费欢等[5]以传感器网络多模态数据流之间的相干性为理论基础,利用多维数据和滑动窗口模型对异常数据及其来源进行检测和评估。Zhao等[6]提出一种基于多分类器集成的漂移补偿监督学习算法,利用支持向量机(Support vector machine, SVM)和改进的长短期记忆(Long short term memory, LSTM)构建多分类器模型,通过归一化和加权策略,在每次分类过程中去除精确度最低的基分类器,使模型适应传感器漂移,有效地提高了传感器漂移分类性能。Wang等[7]利用传感器之间的数据相关性,使用信号空间投影和卡尔曼滤波器实现传感器漂移的盲校准。高鹏等[8]利用LSTM和广义回归神经网络(Generalized regression neural network, GRNN)模型对土壤墒情进行建模,实现对柑橘土壤含水量和土壤电导率的预测。
在传统的机器学习任务中,需要用多种信号处理算法检测数据流中的异常,导致效率较低,在数据分析过程中易出现过拟合或欠拟合现象。此外,大多数据异常检测算法泛化能力较弱,不适用于其他类型的异常检测。文献[6]中采用SVM和LSTM的结合模型,获得了理想精确度,但增加了时间复杂度。文献[7]所提信号空间投影和卡尔曼滤波器方法,利用传感器之间的相关性解决传感器漂移问题,但传感器难以密集部署,模型应用场景狭小、泛化能力较弱。
近年来,随着硬件计算能力的显著提升,人工智能(Artificial intelligence)和深度学习(Deep learning)技术已广泛应用于图像识别[9]、自然语言处理[10]、推荐系统[11]和音频识别[12]领域。深度结构的神经网络在传感器数据异常检测领域也得到广泛应用,Bao等[13]提出了一种基于计算机视觉和深度学习的传感器数据异常检测方法,该方法将时间序列信号转换为图像并保存在灰度图像中,通过训练两隐藏层堆叠的自动编码深度神经网络来自动检测未标签的数据。Tang等[14]提出了一种基于卷积神经网络的传感器数据异常检测方法,在图片中融合数据的时域和频域特征,并采用卷积神经网络对图片进行分类,但时域和频域可视化方法无法保存数据的时间数值依赖性。Liu等[15]提出一种动态宽度增量学习算法,通过深度叠加宽度学习系统,解决数据回归和图像分类问题,但在数据预处理中,未采用有效方法增强数据时间依赖性。Wang等[16]提出一种格拉姆角求和域/差分域和马尔科夫过渡域的时间序列数据可视化方法,并采用平铺卷积神经网络学习图像特征,实现时间序列数据分类,但当原始时间序列过长时,重构后的矩阵规模大,增加了运算时间消耗。
针对以上研究现状,本文设计了一种宽度卷积神经网络(Broad convolution neural network, BCNN)的农情数据异常检测方法,并通过滑动窗口机制解决单次输入模型数据量大引起的模型检测耗时长和准确率不足等问题。研究数据预处理与重构方法、滑动窗口尺寸对异常检测性能的影响,对比分析不同异常检测模型的性能差异,以期为精准农业的数据高质量采集提供参考。
1. 材料与方法
1.1 试验材料
试验数据采用位于安徽省长丰县双墩镇的合肥安谷农业有限公司羊圈监测点传感器的空气湿度、空气温度、土壤湿度和土壤温度数据,时间覆盖范围从2019年12月1日至2019年12月31日,采样间隔3 min,共11355条观测数据。为便于开展检测性能对比分析,在数据中引入一组随机故障率(10%~40%)的异常点[17]。为系统评估所提方法的性能,采用80%的数据集作为训练集、20%的数据集作为测试集。数据集如图1所示,4种数据的周期性和趋势特征存在差异。空气湿度数据值域波动较大,周期性特征不明显。空气温度数据呈周期性变化,波动较小。土壤湿度数据具有明显的周期性特征,值域范围较小。土壤温度数据周期性特征与空气温度数据相似,且值域波动更小。
1.2 异常检测框架
基于宽度学习的农情数据异常检测框架图如图2所示。传感器端负责采集数据并发送至数据中心,数据中心负责存储数据、训练模型和异常检测。模型训练过程如下:部署传感器并采集数据,将数据归一化,基于数据周期和采样间隔等参数确定滑动窗口尺寸l,编码为极坐标表示,并基于滑动窗口尺寸l划分子集,采用格拉姆角求和域(Gramian summation angular field, GASF)方法重构为矩阵,最后训练得到BCNN数据异常检测模型。
![]() 图 2 基于BCNN的传感器数据异常检测框架Figure 2. Anomaly detection framework of sensor data based on BCNN
图 2 基于BCNN的传感器数据异常检测框架Figure 2. Anomaly detection framework of sensor data based on BCNN在异常数据实时检测过程中,数据中心对采集的最新数据进行归一化处理,编码为极坐标并重构矩阵,最后输入模型检测异常。若模型判断为正常,则将其保存为历史数据,否则,校准异常并保存。校准异常可采用回归模型预测、均值替换等方法[18]。
1.3 数据预处理
设传感器节点在某时刻共采集到n个时间序列数据
$ X = \{ {x_1},{x_2}, \cdots ,{x_n}\} $ ,为降低采样数据取值范围对模型训练效果的影响,将数据归一化至[−1,1]区间内,表示为:$$ x'_i = \frac{{({x_i} - {X_{\max }}) + ({x_i} - {X_{\min }})}}{{{X_{\max }} - {X_{\min }}}},i \in [1,n],x'_i \in {X'}, $$ (1) 式中,xi表示原始时间序列数据,X'
表示归一化后的时间序列数据,Xmax和Xmin分别表示原始时间序列中的最大值和最小值, $ x'_i $ 表示归一化后的数据。归一化将原始数据映射至[−1,1]区间内,将有量纲数据转化为无量纲形式,降低不同量纲对模型的影响,并保留原始数据特征,使不同的数据集处于相同数量级,便于对比分析。模型处理一维时间序列时,无法有效保持数据周期性时间依赖,无法有效提取部分数据之间的相关性,且对于具有不同周期的时间序列数据,模型泛化能力较差。为此,本文通过将时间序列数据编码为极坐标并重构为矩阵,实现模型对时间序列数据时间依赖性的保持和泛化性的增强。
具体的,将归一化后的数据编码为极坐标[16],时间序列数据的数值和时间戳分别编码为极角和极径,表示为:
$$ \begin{array}{l} \theta = \arccos x'_i,x'_i \in {X'} ,\\ r = \dfrac{{{t_i}}}{n},{t_i} \in [1,2,3, \cdots ,n] ,\end{array} $$ (2) 式中,ti表示时间序列数据的时间戳,n表示时间序列数据数量,θ和r分别表示编码后数据的极径和极角。基于极坐标的编码方法是预处理和分析时间序列数据的一种新方法。反余弦函数在[−1,1]区间内是单调的,因此,式(2)在时间序列数据和极坐标之间构建了一个双射。给定一组时间序列数据,可产生唯一的映射关系,且相对笛卡尔坐标系,极坐标可保留绝对时间关系。
滑动窗口控制单次输入模型的数据量,是影响异常检测模型性能的重要参数,选取合适的滑动窗口尺寸可有效提高模型准确率和降低时间消耗。本文设计了基于数据特征的滑动窗口尺寸l的计算方法:
$$ l=\Bigg(\frac{\Delta t}{\beta }+\ln S\Bigg)T{{\text{e}}^{-\beta {{\log }_{2}}\sqrt{{}^{T} \diagup {}_{\Delta t}\;}}}, $$ (3) 式中,β为支持度衰减因子,Δt为农业物联网传感器数据采样间隔,T为农情数据特征周期,S为农情数据的标准差。滑动窗口尺寸对模型准确率和效率存在影响,窗口尺寸过大会增加模型检测耗时,过小则会导致模型无法有效提取数据特征,从而降低准确率。式中T/Δt控制滑动窗口选择函数上升幅度和衰减速度,Δt/β+ln S平衡采样间隔和数据特征的影响,可满足模型异常检测准确率和效率需求。
根据滑动窗口尺寸l,将编码后的数据分为若干个子集
$ \left\{ {\theta' _1, \cdots ,\theta' _l} \right\},\left\{ {\theta' _{l + 1}, \cdots ,\theta' _{2l}} \right\}, \cdots $ ,并将每个子集数据采用GASF方法重构为矩阵,采用类热力图形式可视化:$$ {\boldsymbol{G}} = \left( {\begin{array}{*{20}{c}} {\cos (\theta' _1 + \theta' _1)}& \cdots &{\cos (\theta' _1 + \theta' _l)} \\ \vdots & \ddots & \vdots \\ {\cos (\theta' _l + \theta' _1)}& \cdots &{\cos (\theta' _l + \theta' _l)} \end{array}} \right) \text{,} $$ (4) 式中,G为重构后的矩阵,
$ \theta' _1 $ 和$ \theta' _l$ 为编码为极坐标并划分子集后的数据。通过式(2)将归一化后的数据编码为极坐标,采用式(3)重构为矩阵。时间序列数据编码为极坐标后仍保留数据连续性,重构后的矩阵随着位置的变化,时间会增加,可有效保存时间依赖性。此外,矩阵也包含了时间相关性,其中的Gi,j元素叠加了原始数据中第i和第j个数据相关性,主对角线包含了原始数据信息。因此,可采用神经网络提取高维数据特征。
为展示完整的数据预处理方法,以土壤湿度数据为例,完整流程如图3所示。首先,采用式(1)将原始土壤湿度数据归一化至[−1,1]区间内,并通过式(2)编码为极坐标表示(图3B),极坐标数据保留时间依赖性,原始异常数据在极坐标系中仍存在离群特征(即极坐标图中存在显著的异常点),接着,采用式(3)将极坐标数据划分子集,并通过式(4)重构矩阵。图3C展示了部分矩阵,异常数据可在GASF矩阵中显著表示,矩阵中出现颜色突变即表示该点数据存在异常,如矩阵1、2、5、6和7,矩阵中颜色连续变化即表示无异常,如矩阵3、4和8。预处理后的数据特征更为显著,可采用模型更有效地检测异常数据。
1.4 宽度卷积神经网络框架
设计的宽度卷积神经网络结构如图4所示。模型采用宽度学习系统强化传统CNN模型[19]。BCNN的第1层(Layer 1)是输入层,输入矩阵维度为k×k,其中k表示滑动窗口尺寸。第2层(Layer 2)是卷积层,其中卷积核(Filter)数量为20,每个卷积核尺寸为41×41,步长(Stride)为1,采用Relu激活函数。第3层(Layer 3)是Reduction层,其中包含1个池化模块和2个卷积模块,该层采用残差连接。池化模块中,池大小(Pool size)为3×3,步长为3,池化方式为最大池化(Maxpooling)。卷积模块中,第1层卷积采用1×1的卷积核,第2层卷积采用20个3×3大小的卷积核,步长为3。卷积模块和池化模块输出的特征图按其深度连接,并采用Relu函数激活,被平坦化为一维向量输入宽度学习系统。第4层(Layer 4)采用特征提取器代替传统CNN模型中的Softmax分类器,其中包含1000个特征节点。第5层(Layer 5)为特征增强器,其中包含1000个特征增强节点,第4层中特征提取器的输出被特征增强器随机映射输出。最后将特征提取器和特征强化器的输出连接,并加权重构,得到整个模型的输出。
卷积可通过连续地变换提取数据的复杂特征。在卷积层中,利用卷积核对输入数据进行卷积:
$$ x_i^l = {\rm{Relu}}\Bigg(\sum\limits_{n = 1}^N {x_n^{l - 1}} f_{n,i}^l\Bigg) \text{,} $$ (5) 式中,
$ x_i^l $ 表示第l层中图片的$ i $ 通道,$ f_{n,i}^l $ 表示位于第l层中第n个卷积核的i通道,N表示l−1层中通道总数,Relu()表示激活函数。池化是一种降采样形式。它将图像划分为若干个区域,每个区域独立地按池化方式输出,减小了数据空间大小,参数数量和模型计算量也随之下降,在一定程度上防止过拟合的发生。本文采用最大池化方式,表示为:
$$ a_{i,n}^l = \max (a_{i,n}^{l - 1}, \cdots ,a_{i,m}^{l - 1}) \text{,} $$ (6) 式中,
$ a_{i,n}^l $ 表示网络l层中图片i通道的第n个位置,$a_{i,n}^{l - 1},\cdots ,a_{i,m}^{l - 1}$ 表示网络l−1层中图片i通道的池化区域对应的第n到m个位置。宽度学习系统[15]是一种通过随机方法将特征扩展到广阔空间的模型,其主要由特征节点和增强节点组成。特征节点将输入随机映射,映射特征由增强节点随机扩展,将最后所有特征加权连接输出。
残差层的输出被平坦化为一维向量X并输入至特征节点,其表示为:
$$ {{\boldsymbol{Z}}_i} = \phi ({\boldsymbol{X}}{{\boldsymbol{W}}_{{z_i}}} + {{\boldsymbol{\beta}} _{{z_i}}}),i = 1,2, \cdots ,n , $$ (7) 式中,权重矩阵
$ {{\boldsymbol{W}}_{{z_i}}} $ 和偏置矩阵$ {{\boldsymbol{\beta}} _{{z_i}}} $ 随机生成,$ \phi ( ) $ 表示激活函数,Zi表示第i个特征节点的输出,所有特征节点的集合记为$ {{\boldsymbol{Z}}^n} = [{{\boldsymbol{Z}}_1}, \cdots ,{{\boldsymbol{Z}}_n}] $ ,其中n为特征节点数量。类似的,特征增强节点可表示为:$$ {{\boldsymbol{H}}_j} = \xi ({{\boldsymbol{Z}}^n}{{\boldsymbol{W}}_{{h_j}}} + {{\boldsymbol{\beta}} _{{h_j}}}),j = 1,2, \cdots ,m , $$ (8) 式中,权重矩阵
$ {{\boldsymbol{W}}_{{h_j}}} $ 和偏置矩阵$ {{\boldsymbol{\beta}} _{{h_j}}} $ 随机生成,$ \xi () $ 表示激活函数,Hj表示第j个特征增强节点的输出,所有特征节点的集合记为$ {{\boldsymbol{H}}^m} = [{{\boldsymbol{H}}_1}, \cdots ,{{\boldsymbol{H}}_m}] $ ,其中m为特征增强节点数量。将特征节点和特征增强节点连接加权重构,输出可表示为:
$$ {\boldsymbol{Y}} = \left[ {{{\boldsymbol{Z}}_1}, \cdots ,{{\boldsymbol{Z}}_n}|{{\boldsymbol{H}}_1}, \cdots ,{{\boldsymbol{H}}_m}} \right]{\boldsymbol{W}} = \left[ {{{\boldsymbol{Z}}^n}|{{\boldsymbol{H}}^m}} \right]{\boldsymbol{W}} \text{,} $$ (9) 式中,权重矩阵W可通过伪逆法求解,可表示为:
$$ {\boldsymbol{W}} = {\left[ {{{\boldsymbol{Z}}^n}|{{\boldsymbol{H}}^m}} \right]^\dagger }{\boldsymbol{Y}} = {({{\boldsymbol{A}}^m})^\dagger }{\boldsymbol{Y}} \text{,} $$ (10) 式中,
${{\boldsymbol{A}}^m}$ =$\left[ {{{\boldsymbol{Z}}^n}|{{\boldsymbol{H}}^m}} \right]$ ,${({{\boldsymbol{A}}^m})^\dagger }$ 表示${{\boldsymbol{A}}^m}$ 的伪逆,可通过极限方法求得:$$ {{\boldsymbol{A}}^\dagger } = \mathop {\lim }\limits_{\lambda \to 0} {(\lambda {\boldsymbol{I}} + {\boldsymbol{A}}{{\boldsymbol{A}}^{\rm{T}}})^{ - 1}}{{\boldsymbol{A}}^{\rm{T}}} \text{,} $$ (11) 式中,
${\boldsymbol{A}}$ 表示特征节点和增强节点输出组合成的扩展矩阵,λ表示对权重矩阵W的约束,I表示单位矩阵,AT表示转置矩阵。1.5 检测性能评价指标
本文采用准确率(Accuracy)、F1值和模型检测时间(Time)等指标评估模型的异常检测性能,其表示为:
$$ 准确率=\frac{{T}_{\text{p}}+{T}_{\text{n}}}{{T}_{\text{p}}+{T}_{\text{n}}+{F}_{\text{p}}+{F}_{\text{n}}} \text{,} $$ (12) $$ 精确度=\frac{{T}_{\text{p}}}{{T}_{\text{p}}+{F}_{\text{p}}} \text{,} $$ (13) $$ 召回率=\frac{{T}_{\text{p}}}{{T}_{\text{p}}+{F}_{\text{n}}} \text{,} $$ (14) $$ F1值=\frac{2\times 精确度\times 召回率}{精确度+召回率} \text{,} $$ (15) 式中,Tp表示正确分类至目标类的数量,Fp表示其他类错误分类至目标类的数量,Tn表示其他类正确分类的数量,Fn表示目标类错误分类至其他类的数量。
准确率是正确分类的数据与数据集数据总量的比值,反映模型的正确检测能力。精确度(Precision)和召回率(Recall)分别是正确分类为异常数据的个数与所有分类的异常数据、实际异常数据的比值。F1值同时兼顾了精确度和召回率。除异常检测能力外,模型检测时间也是评估模型是否符合实际应用的重要参数。
2. 试验与分析
2.1 试验环境与参数
试验采用Windows 10操作系统、Intel Core i5 CPU、8GB内存的台式计算机,Python3.6编程语言和Tensor Flow2.0.0框架用于异常检测模型搭建和应用。主要研究滑动窗口尺寸对模型异常检测性能的影响及模型对不同特征数据的异常检测灵敏性,以甄选最优的异常检测方法。在此基础上,对比分析不同异常检测模型性能。
试验将BCNN与当前使用较为广泛的SVM、随机森林(Random forest, RF)和卷积神经网络方法进行比较。SVM模型[20-21]核函数采用径向基函数(Radial basis function, RBF),核函数参数ε为0.2,正则化参数C为1;RF模型[22]聚类数c=2,模糊程度系数m=3,卷积神经网络方法从文献[14]中引用。BCNN模型的特征节点和特征增强节点数量均为1000。对于滑动窗口,传感器监测数据特征周期T为24 h,支持度衰减因子β取0.5[23],采样间隔Δt为3 min,空气湿度、空气温度、土壤湿度和土壤温度的滑动窗口尺寸分别为105、88、76和91。为控制模型参数随机初始化和训练引起的随机性,重复5次试验,以平均数进行结果分析。
2.2 滑动窗口尺寸对检测性能的影响
为评估所提滑动窗口选择方法的有效性,以BCNN模型为例,采用窗口尺寸60~120的数据集进行试验,结果如图5所示。空气湿度数据集中,异常检测准确率在窗口尺寸[60,100]区间内呈上升趋势,在窗口尺寸100时达到峰值;空气温度数据集中,窗口尺寸在[60,90]区间时,异常检测准确率随窗口尺寸增大而增加,窗口尺寸在90时准确率表现最佳,窗口尺寸大于90时准确率无显著变化;土壤湿度数据集中,在窗口尺寸[60,70]区间内准确率呈增加趋势,在[70,120]区间内准确率趋于稳定;土壤温度数据集中,在窗口尺寸[90,100]时准确率最高。值得注意的是,土壤湿度数据集呈最高准确率的窗口尺寸远小于其他数据集,这是由于其数据波动不显著,模型仅需少量数据即可学习其特征。试验所得出的最佳滑动窗口尺寸,与式(3)得出的窗口尺寸基本相符。因此,基于数据特征的滑动窗口选择方法可有效地提高模型异常检测准确率。
![]() 图 5 不同滑动窗口尺寸与数据集的异常检测准确率Figure 5. Anomaly detection accuracy of different sliding window sizes and datasets
图 5 不同滑动窗口尺寸与数据集的异常检测准确率Figure 5. Anomaly detection accuracy of different sliding window sizes and datasets模型检测耗时随滑动窗口尺寸变化如图6所示。空气湿度数据集中,滑动窗口尺寸在[90,100]区间时,检测耗时最短。空气温度数据集中,在窗口尺寸[80,100]区间时检测耗时最短,处于理想状态。土壤湿度数据集中,当窗口尺寸变化时,模型检测耗时变化不明显,窗口尺寸80左右时检测耗时最短。土壤温度数据集中,在窗口尺寸[80,90]区间内,检测耗时较短,处于理想水平,其中窗口尺寸90时最优。总体上,窗口尺寸和检测耗时呈二次相关。波动性较强的数据(如空气湿度),窗口尺寸变化时,检测耗时波动更大;而波动小、较为平稳的数据(如土壤湿度),改变滑动窗口尺寸对检测耗时影响较小。
![]() 图 6 不同滑动窗口尺寸与数据集的模型检测耗时Figure 6. Anomaly detection time of different sliding window sizes and datasets
图 6 不同滑动窗口尺寸与数据集的模型检测耗时Figure 6. Anomaly detection time of different sliding window sizes and datasets综上,采用滑动窗口机制后,可提升模型对异常数据的检测能力,针对不同特征数据选取合适的滑动窗口尺寸,可提升异常检测准确率和降低检测耗时。
2.3 模型异常检测性能
对比分析SVM、RF、CNN和BCNN模型的数据异常检测性能,各种模型的异常检测准确率和F1值如图7所示。BCNN模型在空气湿度、空气温度、土壤湿度和土壤温度数据集上均表现出良好的异常检测性能,准确率均在97%以上,其中空气湿度数据集的准确率最高,达到99.29%,优于SVM、RF和CNN的95.68%、94.67%和93.31%。相较于CNN模型,BCNN模型在空气湿度、空气温度、土壤湿度和土壤温度数据集上准确率分别提升了5.98%、1.48%、2.19%和2.55%;相较于SVM和RF模型,BCNN模型在空气湿度数据集上的准确率与二者差异最为明显,分别高出3.61%和4.62%。由图1可知,空气湿度数据波动性较大,周期性特征弱于其他数据集,故BCNN在处理波动性大的数据时性能更佳。BCNN模型在空气湿度、空气温度、土壤湿度和土壤温度数据集上的F1值分别为:0.996 4、0.9887、0.9949和0.9920,均优于其他模型。空气温度数据集中,4种模型的F1值差值较小,均小于0.0076。在波动性较大的空气湿度数据集中,BCNN模型的F1值达到0.9964,分别优于SVM、RF和CNN模型0.0188、0.0241和0.0310。因此,BCNN模型异常检测性能优于其他模型,且BCNN模型对波动性大的数据检测能力更优,而其他模型随着数据波动性增大,异常检测能力有所下降。
![]() 图 7 模型异常检测准确率与F1值Figure 7. Anomaly detection accuracy and F1 score of different models
图 7 模型异常检测准确率与F1值Figure 7. Anomaly detection accuracy and F1 score of different models总之,相较于传统机器学习算法和深度学习模型,BCNN模型对异常数据的检测能力在不同特征的数据集上均得到了一定程度的提升。其中,对波动性较大的数据集的异常检测能力最优。
各种异常检测模型检测耗时如表1所示。BCNN模型检测耗时大幅低于同类的深度模型CNN,仅为其1/6~1/7。相较于SVM和RF传统机器学习算法,BCNN模型虽然需要额外的检测时间,但异常检测准确率和F1值都有明显提升,增强了模型对波动性较大数据的检测能力,同时,BCNN模型的超参数数量较少,有效地降低了超参数选择的复杂度。综上,对于农情数据异常检测,BCNN模型在检测能力和耗时方面优于同类深度学习模型,在检测能力和超参数选择方面优于传统机器学习算法,具有良好的适用性。
表 1 不同模型异常检测耗时Table 1. Anomaly detection time of different modelss 模型
Model空气湿度 Air humidity 空气温度 Air temperature 土壤湿度 Soil humidity 土壤温度 Soil temperature SVM 10.78 14.62 11.58 14.47 RF 12.02 14.39 12.85 13.77 CNN 2 073.04 2 014.88 1 928.76 2 116.24 BCNN 335.74 329.19 283.32 291.96 3. 结论
本研究提出了基于宽度卷积神经网络的农情数据异常检测方法,采用养殖场传感器环境监测数据,综合评估了数据异常检测性能。试验结果表明,基于数据特征的滑动窗口划分子集,可有效地增加模型检测准确率和降低检测耗时。在异常检测模型对比试验中,BCNN模型取得了最高准确率和F1值,对空气和土壤温湿度数据异常检测的平均准确率和F1值分别达到了98.54%和0.993 0,相比于SVM、RF和CNN模型的平均准确率(96.86%、95.79%和95.49%)和F1值(0.983 7、0.978 1和0.9768),表现出良好的检测效果。BCNN模型对波动性较大数据集的检测能力更强,准确率和F1值平均优于其他模型4.74%和0.0246。另一方面,BCNN模型检测时间仅为同类深度学习模型CNN的1/6~1/7,且比传统机器学习模型SVM和RF采用更少的超参数。本研究为农业物联网数据高质量感知及农业信息化提供了一定的参考。考虑到无线传感器网络规模不断扩展,后续研究将更多地关注传感器网络群体异常数据检测,进一步提高农业物联网感知数据质量。
-
![]()
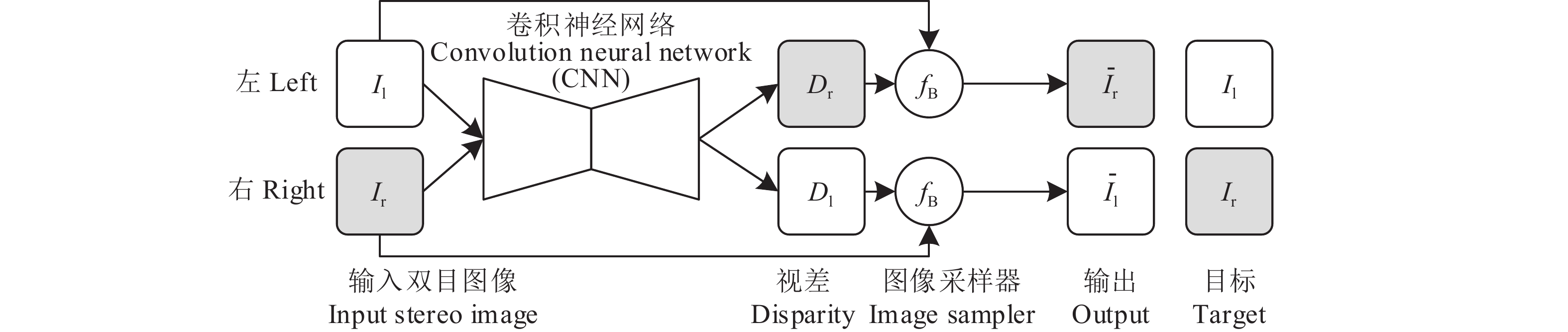
图 1 自监督深度估计模型
Il、Ir分别表示左、右目图像;Dl、Dr分别表示左、右目视差图;$ {\bar I_{\rm{l}}} $、$ {\bar I_{\rm{r}}} $分别表示左、右目重构图像;fB表示图像采样器
Figure 1. Self-supervised depth estimation model
Il and Ir are left and right images respectively; Dl and Dr are left and right disparity maps respectively; $ {\bar I_{\rm{l}}} $ and $ {\bar I_{\rm{r}}} $ represent left and right warping images respectively; fB denotes image sampler
![]()
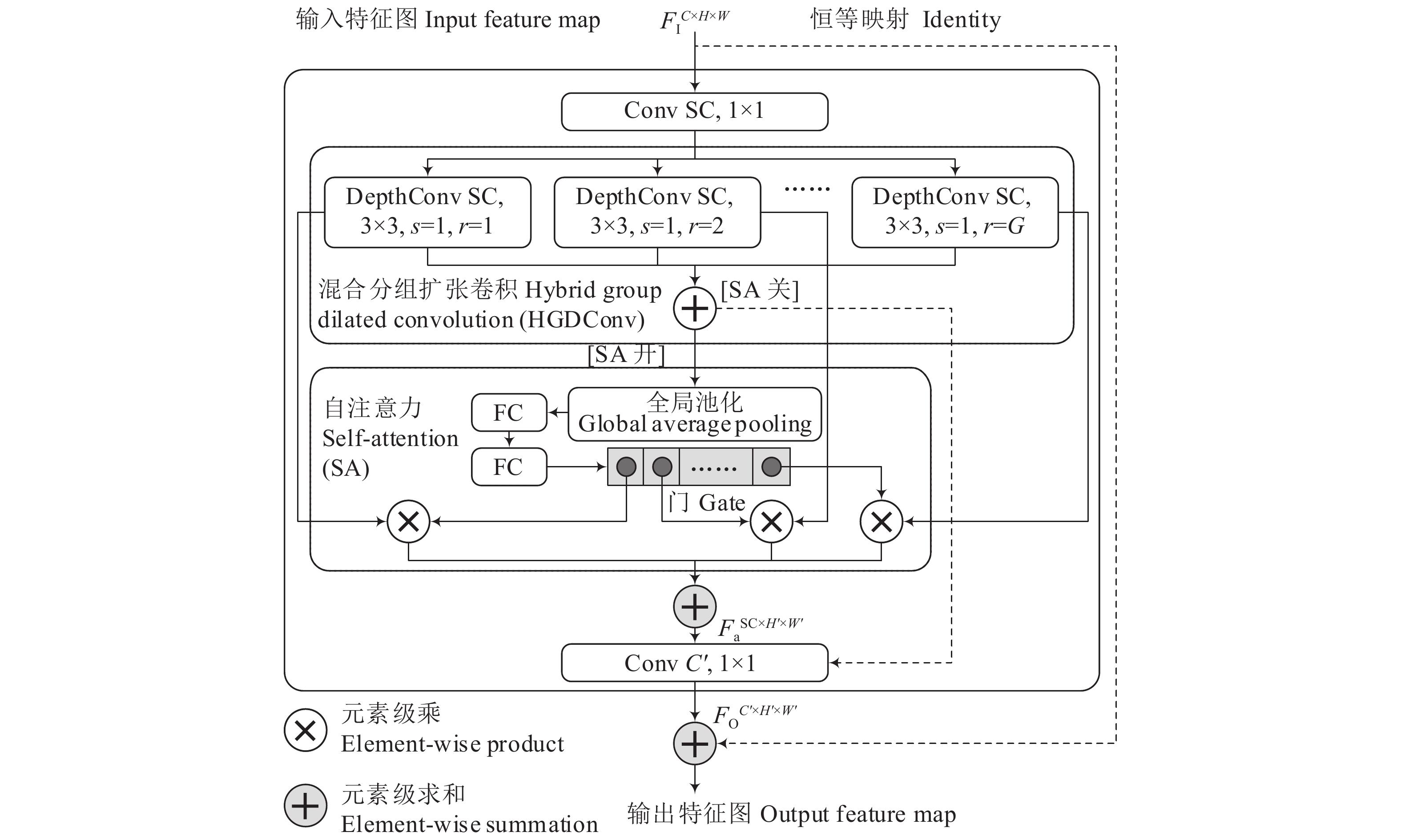
图 2 基于混合分组扩张卷积与自注意力机制的反向残差模块
DepthConv SC,3×3, s=1,r=G等表示通道数为SC、卷积核大小为3×3、步长为1且扩张因子为G的深度化卷积;Conv表示标准卷积;FC表示全连接层;S为扩展因子,G为组数,R为缩减因子,C、C'表示输入、输出特征图通道数
Figure 2. Inverted residual module based on hybrid group dilated convolution and self-attention mechanism
DepthConv SC, 3×3, s=1, r=G represent deep convolutions with SC channels, 3×3 kernel size, 1 stride, and dilation factor of G; Conv denotes regular convolution; FC means fully connected layers; S is expansion factor; G is the number of group; R is reduction factor; C and C' denote the numbers of input and output channels respectively
![]()
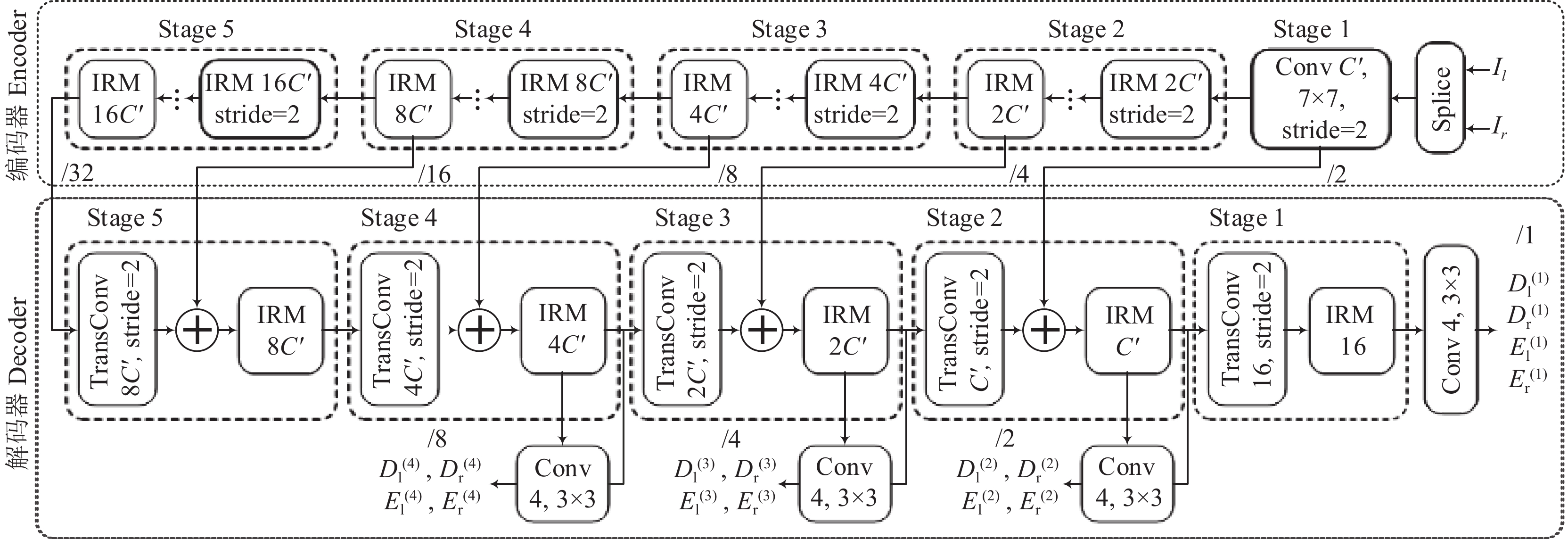
图 3 基于IRM的卷积自编码器
C"为用于调整网络宽度的超参数;TransConv表示转置卷积;$ D_{\rm{l}}^{(1)} $、$ D_{\rm{r}}^{(1)} $、$ E_{\rm{l}}^{(1)} $、$ E_{\rm{r}}^{(1)} $表示多尺度视差图及遮罩平面;/2等表示输出步长
Figure 3. IRM-based convolutional auto-encoder
C" is the super parameter used to adjust network width; TransConv stands for transposed convolution; $ D_{\rm{l}}^{(1)} $, $ D_{\rm{r}}^{(1)} $, $ E_{\rm{l}}^{(1)} $ and $ E_{\rm{r}}^{(1)} $ denote multi-scale disparity maps and mask planes; /2 and so on denote output stride
![]()
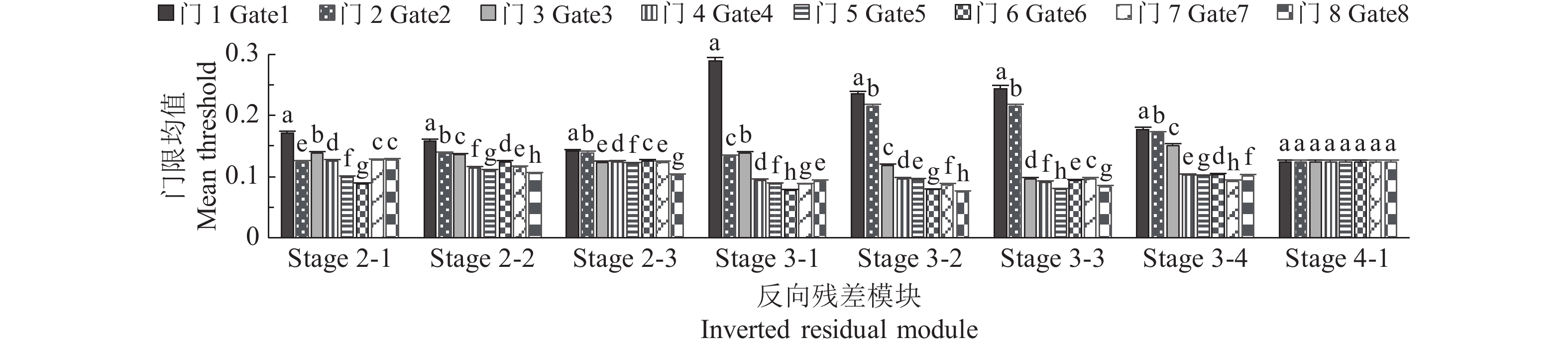
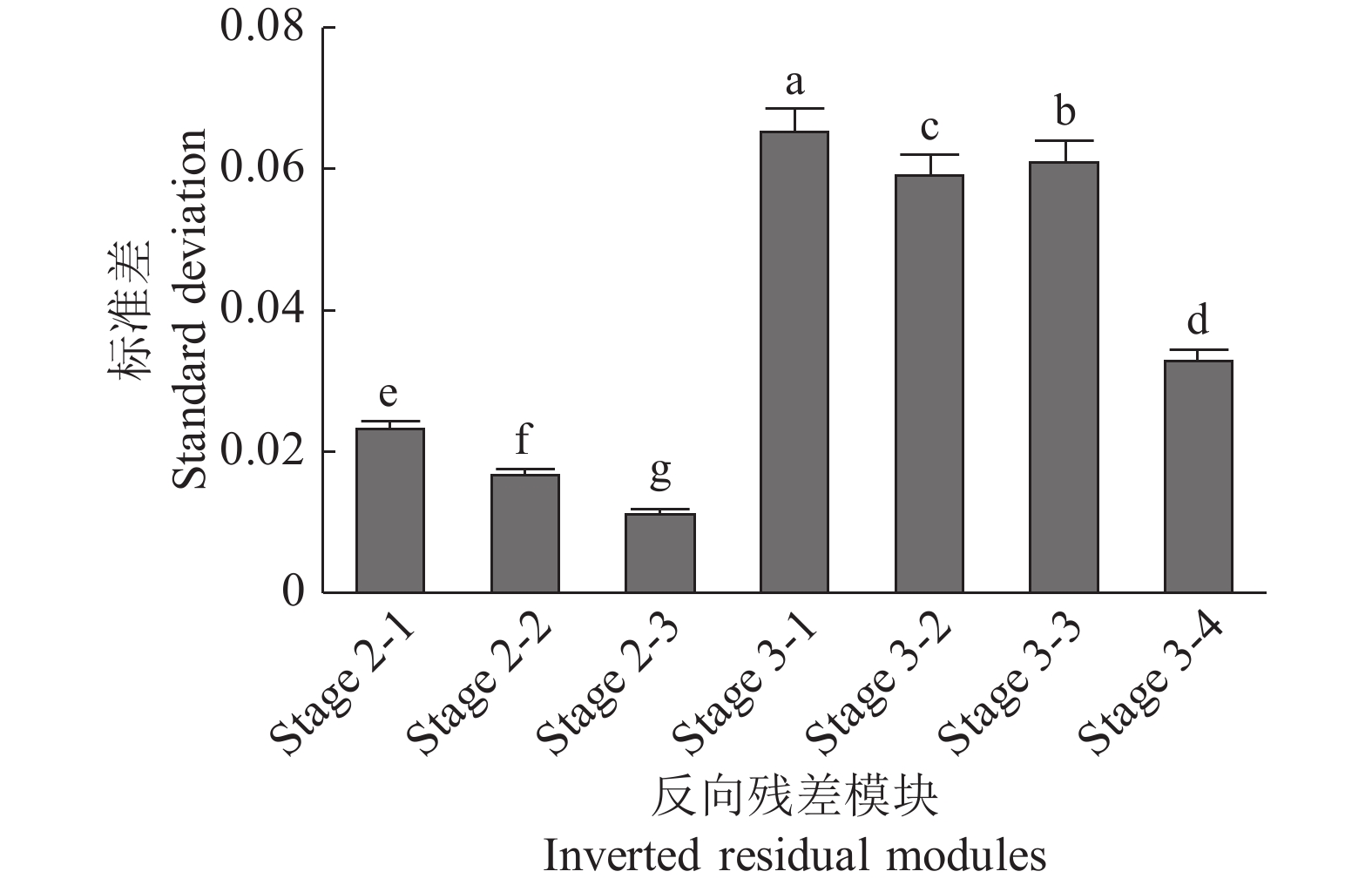
图 5 各反向残差模块(IRMs)门限均值比较
Stage i-j表示Stage i的第j个IRM;同一模块的不同小写字母表示差异显著(P< 0.05,Duncan’s法)
Figure 5. Comparison of mean threshold for inverted residual modules (IRMs)
Stage i-j represent the j IRM of stage i; Different lowercase letters of the same module indicate significant differences (P< 0.05, Duncan’s method)
![]()
图 6 各反向残差模块(IRMs)组选择向量标准差
Stage i-j等表示Stage i的第j个IRM;图中的不同小写字母表示差异显著(P< 0.05,Duncan’s 法)
Figure 6. Standard deviation of selection vector for each inverted residual modules group
Stage i-j represent the j IRM of stage i; Different lowercase letters indicate significant differences (P<0.05, Duncan’s method)
![]()
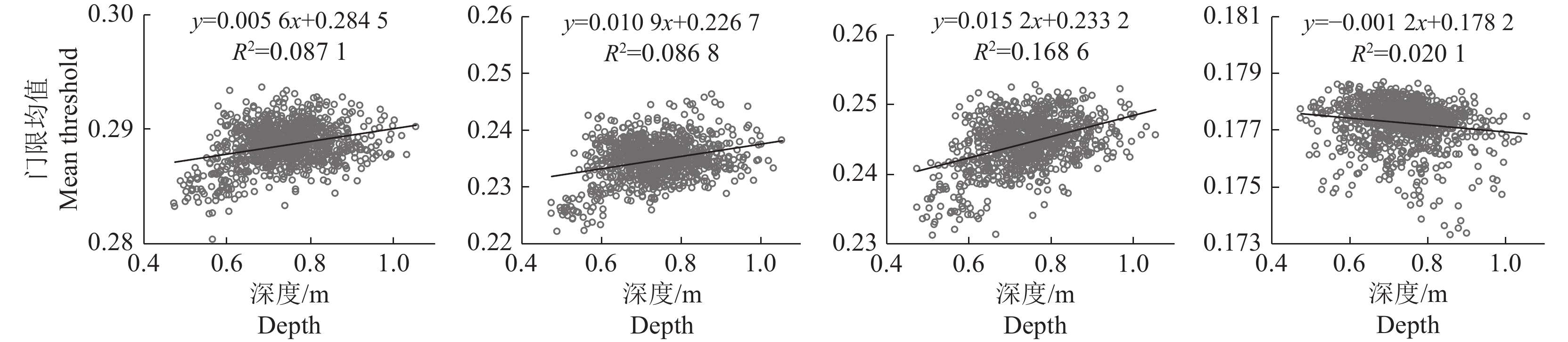
图 7 门限均值与图像平均深度的关系
Figure 7. Relationship between mean threshold and mean depth of image
![]()
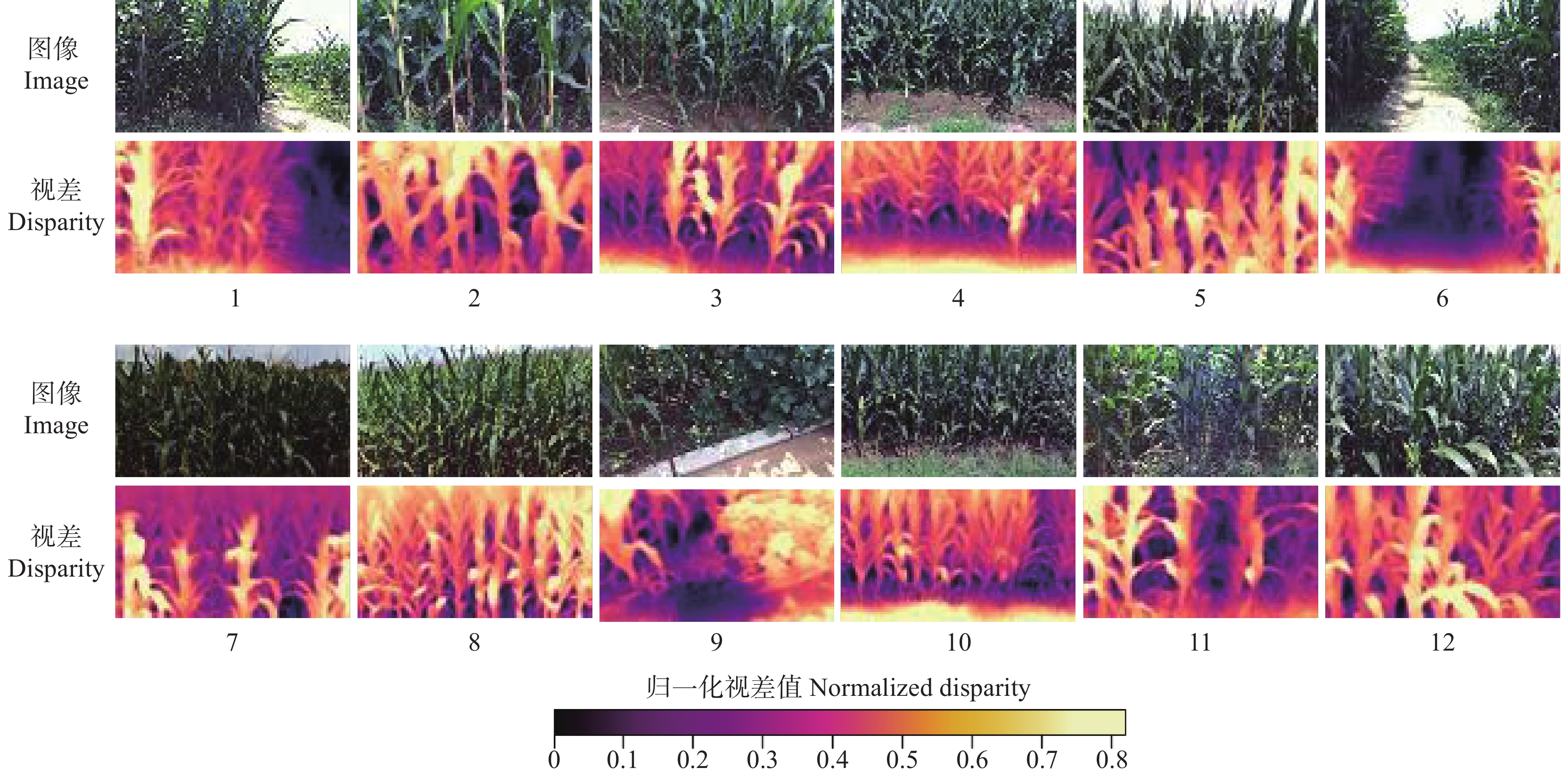
图 8 田间玉米植株图像深度估计示例(1~12)
Figure 8. Examples (1−12) of depth estimation for corn plant image
表 1 不同深度估计模型的测试结果1)
Table 1 Test results for different depth estimation models
模型
Model处理 Treatment 深度估计误差 Depth estimation error 阈值限定精度/% Accuracy with threshold 混合扩张
Hybrid
dilation梯度纹理
Gradient and
texture自注意力
Self-attentionRel/% Sq Rel/mm RMSE/mm RMSElg MAE/mm MRE/mm $ \delta < 1.15 $ $ \delta < {1.15^2} $ $ \delta < {1.15^3} $ A 20.8±0.08a 85.3±0.87a 667.0±2.0a 0.1364±0.0007a 249.7±1.1a 272.8±2.3a 80.8±0.35b 85.2±0.23b 89.0±0.31b B √ 7.5±0.02b 66.9±0.67b 599.2±2.0c 0.0764±0.0004b 169.1±1.0b 185.6±1.1b 93.0±0.14a 95.5±0.19a 96.6±0.10a C √ √ 7.3±0.02c 64.9±0.34c 625.1±1.8b 0.0739±0.0002c 167.2±1.0c 184.9±1.7c 92.5±0.20a 95.7±0.14a 97.0±0.12a D √ √ √ 6.7±0.02d 58.0±0.47d 568.2±2.0d 0.0722±0.0002d 161.0±1.0d 177.0±3.4d 93.9±0.13a 96.0±0.20a 97.2±0.09a 1) Rel:平均相对误差,Sq Rel:平方相对误差,MAE:平均绝对误差,MRE:平均距离误差;同列数据后的不同小写字母表示不同模型间差异显著(P<0.05,Duncan’s法)
1) Rel: Mean relative error, Sq Rel: Squared relative error, MAE: Mean absolute error, MRE: Mean range error; Different lowercase letters in the same column indicate significant differences among different models (P<0.05, Duncan’s method) 下载: 导出CSV
下载: 导出CSV
表 2 结构超参数对深度估计性能的影响1)
Table 2 Effects of structural hyper parameters on depth estimation performance
模型2)
Model深度估计误差 Depth estimation error 阈值限定精度/% Accuracy with threshold 参数(×106)
Parameter速度/
(帧·s−1)
SpeedRel/% Sq Rel/mm RMSE/mm RMSElg MAE/mm MRE/mm δ < 1.15 δ < 1.152 δ < 1.153 C (2, 8, —) 7.3±0.02e 64.9±0.34d 623.4±1.8b 0.0741±0.0001d 170.7±1.0c 183.7±1.0c 93.5±0.20abc 95.7±0.14ab 97.0±0.12a 2.70 15.7±0.1e C1 (1, 8, —) 7.8±0.05c 79.1±0.82b 723.6±1.9a 0.0764±0.0002c 188.2±1.0a 204.3±1.1a 93.2±0.15bc 95.6±0.15ab 96.9±0.10ab 1.35 20.2±0.5c C2 (4, 8, —) 7.0±0.05f 58.7±0.58e 564.7±2.0f 0.0719±0.0003e 151.6±1.1f 163.5±1.1f 94.2±0.15a 95.9±0.12ab 97.0±0.17a 5.40 10.6±0.1g C3 (2, 2, —) 11.2±0.01a 88.1±0.47a 588.7±1.8d 0.0953±0.0001a 184.3±1.0b 198.7±1.1b 89.7±0.27d 92.8±0.17c 95.0±0.10c 2.44 28.0±0.1a C4 (2, 4, —) 8.0±0.02b 69.7±0.59c 612.8±1.8c 0.0789±0.0005b 169.7±1.0c 183.6±1.1c 93.0±0.18c 95.2±0.14b 96.5±0.13b 2.52 21.6±0.4b C5 (2, 6, —) 7.4±0.02d 63.8±0.81d 576.4±1.9e 0.0759±0.0004c 160.9±0.9de 173.8±0.9de 93.6±0.17ab 95.6±0.18ab 96.7±0.12ab 2.61 18.5±0.0d D (2, 8, 1) 6.9±0.02f 59.0±0.47e 572.1±2.0ef 0.0723±0.0002e 163.2±1.0d 175.9±1.0d 93.8±0.15abc 95.9±0.20ab 97.1±0.09a 4.98 12.3±0.2f D1 (2, 8, 4) 6.8±0.05f 58.2±0.99e 576.9±1.6e 0.0717±0.0003e 158.6±0.9e 171.7±1.0e 93.9±0.19ab 96.0±0.18a 97.2±0.11a 3.27 12.5±0.1f D2 (2, 8, 8) 7.1±0.03e 59.4±0.65e 567.1±1.7f 0.0735±0.0001d 164.2±0.8d 177.1±1.0d 93.8±0.17abc 95.8±0.22ab 97.0±0.07a 2.99 12.5±0.1f D3 (2, 8, 16) 7.2±0.03e 60.1±0.83e 559.0±1.8g 0.0743±0.0004d 163.7±1.1d 175.6±1.1d 93.6±0.12abc 95.7±0.17ab 97.0±0.10a 2.85 12.4±0.1f 1) Rel:平均相对误差,Sq Rel:平方相对误差,MAE:平均绝对误差,MRE:平均距离误差;同列数据后的不同小写字母表示不同模型间差异显著(P<0.05,Duncan’s法);2)括号中数字依次为超参数S、G和R,其中“—”表示模型不包含R参数
1) Rel: Mean relative error, Sq Rel: Squared relative error, MAE: Mean absolute error, MRE: Mean range error; Different lowercase letters in the same column indicate significant differences among different models (P<0.05, Duncan’s method); 2) The numbers in brackets are super parameters S, G and R in turn, “—” indicates that the model does not contain parameter R
下载: 导出CSV
表 3 编码器架构对深度估计性能的影响1)
Table 3 Effects of encoder architectures on depth estimation performance
模型
Model编码器架构
Encoder architectureC″ 深度估计误差 Depth estimation error 阈值限定精度/% Accuracy with threshold 速度/(帧·s−1)
SpeedRel/% Sq Rel/mm RMSE/mm RMSElg MAE/mm MRE/mm $ \delta < 1.15 $ $ \delta < {1.15^2} $ $ \delta < {1.15^3} $ D1 ResNet50 24 6.9±0.05f 58.4±0.99e 576.4±1.6d 0.0717±0.0003f 158.6±0.9ef 171.7±1.0ef 94.03±0.19a 96.1±0.18a 97.2±0.11a 12.5±0.1e D1a ResNet50 32 7.1±0.03e 57.5±0.75e 537.2±1.7f 0.0736±0.0003e 157.2±1.0f 170.5±1.1f 93.96±0.14a 95.9±0.25a 97.0±0.19a 11.2±0.2f D1b ResNet50 16 8.3±0.06c 71.6±0.94c 620.1±2.0b 0.0804±0.0005c 184.1±1.1c 199.2±0.9c 92.56±0.21c 95.1±0.19bc 96.4±0.18bc 15.1±0.1d D1c ResNet18 24 9.1±0.05b 75.0±0.65b 617.4±1.9b 0.0837±0.0003b 187.6±1.0b 202.5±1.0b 92.51±0.15c 94.7±0.16c 96.1±0.09c 23.9±0.2b D1d ResNet18 32 8.2±0.04c 70.0±0.99c 600.5±1.7c 0.0806±0.0006c 170.5±1.1d 184.1±1.1d 92.82±0.14bc 94.9±0.15bc 96.4±0.17bc 20.7±0.1c D1e ResNet18 16 10.8±0.07a 106.8±0.94a 750.5±1.9a 0.1020±0.0004a 230.4±1.0a 249.3±0.9a 88.78±0.49d 92.2±0.14d 94.1±0.09d 27.4±0.3a D1f ResNet101 24 7.4±0.04d 62.1±0.94d 568.6±1.8e 0.0758±0.0005d 161.8±1.1e 174.6±1.1e 92.51±0.15ab 95.6±0.14ab 96.9±0.18ab 6.3±0.2g 1)Rel:平均相对误差,Sq Rel:平方相对误差,MAE:平均绝对误差,MRE:平均距离误差;同列数据后的不同小写字母表示不同模型间差异显著(P<0.05,Duncan’s法)
1) Rel: Mean relative error, Sq Rel: Squared relative error, MAE: Mean absolute error; MRE: Mean range error; Different lowercase letters in the same column indicate significant differences among different models (P<0.05, Duncan’s method)
下载: 导出CSV
表 4 编码器深层IRMs的自注意力机制对深度估计性能的影响1)
Table 4 Effects of self-attention mechanism of encoder deep IRMs on depth estimation performance
模型
Model移除自注意力阶段
Self-attention detached stage深度估计误差
Depth estimation error阈值限定精度/%
Accuracy with threshold参数
(×106)
Parameter速度/
(帧·s−1)
SpeedRel/% Sq Rel/mm RMSE/mm RMSElg MAE/mm MRE/mm $ \delta < 1.15 $ $ \delta < {1.15^2} $ $ \delta < {1.15^3} $ D1 6.9±0.05a 58.4±0.99a 576.8±1.6a 0.0717±0.0003a 157.9±0.9a 170.6±1.0a 93.9±0.19a 96.0±0.18a 97.2±0.11a 3.27 12.5±0.1fc D1I Stage 4、5 7.0±0.02a 55.8±0.80a 534.3±1.7c 0.0719±0.0003a 154.7±0.9b 167.2±1.0b 94.0±0.11a 96.0±0.06a 97.1±0.09a 2.71 14.3±0.0a D1II Stage 5 7.1±0.02a 58.8±1.01a 560.0±1.9b 0.0722±0.0003a 158.3±1.0a 170.9±0.9a 93.7±0.15a 95.9±0.21a 97.1±0.14a 2.76 13.1±0.1b 1)Rel:平均相对误差,Sq Rel:平方相对误差,MAE:平均绝对误差,MRE:平均距离误差;同列数据后的不同小写字母表示不同模型间差异显著(P<0.05,Duncan’s法)
1) Rel: Mean relative error, Sq Rel: Squared relative error, MAE: Mean absolute error, MRE: Mean range error; Different lowercase letters in the same column indicate significant differences among different models (P<0.05, Duncan’s method)
下载: 导出CSV
表 5 方法间比较1)
Table 5 Comparison of methods
方法
Method深度估计误差 Depth estimation error 阈值限定精度/% Accuracy with threshold Rel/% Sq Rel/mm RMSE/mm RMSElg MAE/mm MRE/mm $ \delta < 1.15 $ $ \delta < {1.15^2} $ $ \delta < {1.15^3} $ D1I 7.0±0.02d 51.1±0.80d 533.3±1.7b 0.0719±0.0003d 155.6±0.9d 167.2±1.0d 94.0±0.11a 96.0±0.06a 96.3±0.09a Monodepth[13] 14.4±0.07b 131.5±1.33b 504.5±2.1b 0.1218±0.0006b 211.2±1.5b 225.2±1.7b 85.9±0.43c 88.5±0.32c 90.3±0.37c Monodepth2[14] 13.5±0.17c 101.5±1.09c 543.4±2.4b 0.1012±0.0006c 187.8±1.8c 198.2±1.6c 87.0±0.17b 91.1±0.07b 93.3±0.11b SGM[34] 27.9±0.26a 932.1±7.05a 2120.0±21.8a 0.1678±0.0034a 676.2±11.7a 728.1±5.6a 80.5±0.44d 81.4±0.33d 81.5±0.18d 1)Rel:平均相对误差,Sq Rel:平方相对误差,MAE:平均绝对误差,MRE:平均距离误差;同列数据后的不同小写字母表示不同方法间差异显著(P<0.05,Duncan’s法)
1) Rel: Mean relative error, Sq Rel: Squared relative error, MAE: Mean absolute error, MRE: Mean range error; Different lowercase letters in the same column indicate significant differences among different methods (P<0.05, Duncan’s method)
下载: 导出CSV
-
[1] MALAVAZI F B P, GUYONNEAU R, FASQUEL J B, et al. LiDAR-only based navigation algorithm for an autonomous agricultural robot[J]. Computers and Electronics in Agriculture, 2018, 154: 71-79. doi: 10.1016/j.compag.2018.08.034
[2] 毛文菊, 刘恒, 王小乐, 等. 双导航模式果园运输机器人设计与试验[J]. 农业机械学报, 2022, 53(3): 27-39. [3] 王亮, 翟志强, 朱忠祥, 等. 基于深度图像和神经网络的拖拉机识别与定位方法[J]. 农业机械学报, 2020, 51(S2): 554-560. [4] 何勇, 蒋浩, 方慧, 等. 车辆智能障碍物检测方法及其农业应用研究进展[J]. 农业工程学报, 2018, 34(9): 21-32. doi: 10.11975/j.issn.1002-6819.2018.09.003 [5] 景亮, 王瑞, 刘慧, 等. 基于双目相机与改进YOLOv3算法的果园行人检测与定位[J]. 农业机械学报, 2020, 51(9): 34-39. doi: 10.6041/j.issn.1000-1298.2020.09.004 [6] 魏建胜, 潘树国, 田光兆, 等. 农业车辆双目视觉障碍物感知系统设计与试验[J]. 农业工程学报, 2021, 37(9): 55-63. doi: 10.11975/j.issn.1002-6819.2021.09.007 [7] 翟志强, 熊坤, 王亮, 等. 采用双目视觉和自适应Kalman滤波的作物行识别与跟踪[J]. 农业工程学报, 2022, 38(8): 143-151. [8] 洪梓嘉, 李彦明, 林洪振, 等. 基于双目视觉的种植前期农田边界距离检测方法[J]. 农业机械学报, 2022, 53(5): 27-33. [9] EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS 2014). Montreal, Canada: ACM, 2014: 2366-2374.
[10] XIE J Y, GIRSHICK R, FARHADI A. Deep3D: Fully automatic 2D-to-3D video conversion with deep convolutional neural networks[C]//14th European Conference on Computer Vision (ECCV 2016). Amsterdam, Netherlands: Springer, 2016: 842-857.
[11] GARG R, BG V K, CARNEIRO G, et al. Unsupervised CNN for single view depth estimation: Geometry to the rescue[C]//14th European Conference on Computer Vision (ECCV 2016). Amsterdam, Netherlands: Springer, 2016: 740-756.
[12] ZHOU T H, BROWN M, SNAVELY N, et al. Unsupervised learning of depth and ego-motion from video[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 6612-6619.
[13] GODARD C, MAC AODHA O, BROSTOW G J. Unsupervised monocular depth estimation with left-right consistency[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 6602-6211.
[14] GODARD C, MAC AODHA O, FIRMAN M, et al. Digging into self-supervised monocular depth estimation[C]//IEEE International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2020: 3827-3837.
[15] 周云成, 邓寒冰, 许童羽, 等. 基于稠密自编码器的无监督番茄植株图像深度估计模型[J]. 农业工程学报, 2020, 36(11): 182-192. [16] PILZER A, XU D, PUSCAS M, et al. Unsupervised adversarial depth estimation using cycled generative networks[C]//2018 International Conference on 3D Vision. Verona, Italy: IEEE, 2018: 587-595.
[17] MIYATO T, KATAOKA T, KOYAMA M, et al. Spectral normalization for generative adversarial networks[EB/OL]. arXiv: 1802.05957. https://arxiv.org/abs/1802.05957.pdf.
[18] WAN Y C, ZHAO Q K, GUO C, et al. Multi-sensor fusion self-supervised deep odometry and depth estimation[J]. Remote Sensing, 2022, 14(5): 1228. doi: 10.3390/rs14051228.
[19] JADERBERG M, SIMONYAN K, ZISSERMAN A, et al. Spatial transformer networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS 2015). Montreal, Canada: ACM, 2015: 2017-2025.
[20] IDRISSA M, ACHEROY M. Texture classification using Gabor filters[J]. Pattern Recognition Letters, 2002, 23(9): 1095-1102. doi: 10.1016/S0167-8655(02)00056-9
[21] RONNEBERGER O, FISCHER P, BROX T. U-net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015). Munich, Germany: Springer, 2015: 234-241.
[22] YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[C]//International Conference on Learning Representations. San Juan, Puerto Rico: IEEE, 2016.
[23] WANG P Q, CHEN P F, YUAN Y, et al. Understanding convolution for semantic segmentation[C]//2018 IEEE Winter Conference on Applications of Computer Vision. Lake Tahoe, NV, USA: IEEE, 2018: 1451-1460.
[24] YU F, KOLTUN V, FUNKHOUSER T. Dilated residual networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017: 636-644.
[25] SZEGEDY C, LIU W, JIA Y Q, et al. Going deeper with convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015: 1-9.
[26] SZEGEDY C, IOFFE S, VANHOUCKE V, et al. Inception-v4, inception-ResNet and the impact of residual connections on learning[C]//Proceedings of the 31st AAAI Conference on Artificial Intelligence (AAAI-17). San Francisco, California, USA: ACM, 2017: 4278-4284.
[27] CHEN Y P, FAN H Q, XU B, et al. Drop an octave: Reducing spatial redundancy in convolutional neural networks with octave convolution[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul, Korea: IEEE, 2020: 3434-3443.
[28] CHOLLET F. Xception: Deep learning with depth wise separable convolutions[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017: 1800-1807.
[29] SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: Inverted residuals and linear bottlenecks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 4510-4520.
[30] HOWARD A, SANDLER M, CHEN B, et al. Searching for MobileNetV3[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul, Korea: IEEE, 2020: 1314-1324.
[31] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 7132-7141.
[32] KINGMA D P, BA J. Adam: A method for stochastic optimization[J]. Computer Science, 2014.
[33] HIRSCHMÜLLER H. Stereo processing by semiglobal matching and mutual information[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(2): 328-341. doi: 10.1109/TPAMI.2007.1166
[34] SMOLYANSKIY N, KAMENEV A, BIRCHFIFLD S. On the importance of stereo for accurate depth estimation: An efficient semi-supervised deep neural network approach[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Salt Lake City, UT, USA: IEEE, 2018: 11200-11208.
-
期刊类型引用(6)
1. 贾鹿,赵磊,凌飞,李广亚. 基于归一化RBFNN的油井动液面测量数据异常辨识. 电子测量技术. 2024(24): 188-194 .  百度学术
百度学术
2. 李志臣,凌秀军,李鸿秋,李志军. 基于改进ShuffleNet的板栗分级方法. 山东农业大学学报(自然科学版). 2023(02): 299-307 . 百度学术
3. 郑显润,郑鹏,王文秀,程亚红,苏宇锋. 基于多尺度特征提取深度残差网络的水稻害虫识别. 华南农业大学学报. 2023(03): 438-446 . 本站查看
4. 邓雪阳,邓达平,苏万靖. 基于并行深度卷积神经网络的舰船通信异常数据检测研究. 舰船科学技术. 2023(15): 119-122 . 百度学术
5. 杨亚琦,李博雄,杨东霞,刘燕. 基于信息熵的异常数据判别方法. 科学技术创新. 2023(24): 194-199 . 百度学术
6. 杜肖鹏,李恺,王春辉,侯永,尹义蕾,潘守江,张凌风. 国内温室空气温湿度检测及传输技术研究进展. 农业工程技术. 2022(34): 28-34 . 百度学术
其他类型引用(1)













































计量
- 文章访问数: 117
- HTML全文浏览量: 30
- PDF下载量: 27
- 被引次数: 7
