Optimization of culture condition of Metarhizium anisopliae for destruxin A production by response surface methodology
-
摘要:目的
优化绿僵菌Metarhizium anisopliae产绿僵菌素A的培养条件,提高绿僵菌素的产量。
方法应用响应面法设计试验,以Plackett-Burman试验设计和中心组合试验设计筛选得到影响绿僵菌液体发酵的关键因素。
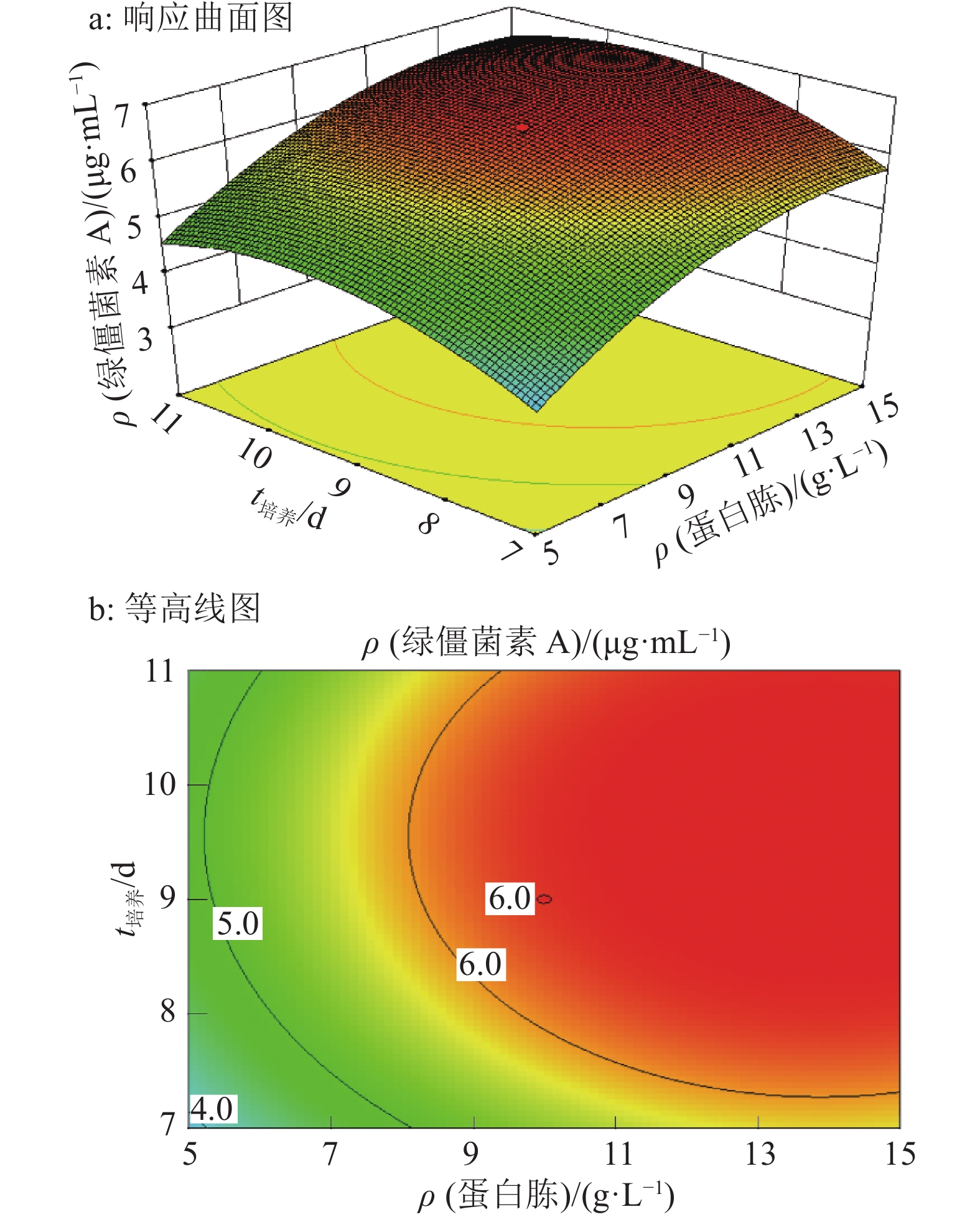
结果试验得到1个拟合程度高、误差小的模型,该模型给出的最佳培养条件为:蔗糖22.7 g·L–1、蛋白胨13.4 g·L–1和发酵时间9.70 d,预测绿僵菌素A最大质量浓度为6.90 μg·mL–1,实际测得质量浓度为6.89 μg·mL–1。
结论结果可为绿僵菌大规模发酵获得粗毒素提供理论依据,使绿僵菌粗毒素的广泛开发与应用成为可能。
Abstract:ObjectiveTo raise the destruxin A production of Metarhizium anisopliae by optimizing culture conditions of liquid fermentation.
MethodExperiments were designed by response surface methodology (RSM). The key factors affecting the liquid fermentation were screened by Plackett-Burman design and central composite design.
ResultA model with high fitting degree and small error was obtained. The optimum culture condition of this model was 22.7 g·L–1 sucrose, 13.4 g·L–1 peptone and 9.70 d for fermentation. The maximum predicted concentration of destruxin A was 6.90 μg·mL–1, while the actual measured concentration was 6.89 μg·mL–1.
ConclusionThe results can provide a theoretical basis for large-scale fermentation of M. anisopliae and production of crude toxin, which can potentially enable the widespread development and application of crude toxin.
-
Keywords:
- Metarhizium anisopliae /
- destruxin /
- yield /
- response surface methodology /
- liquid fermentation /
- culture condition
-
-
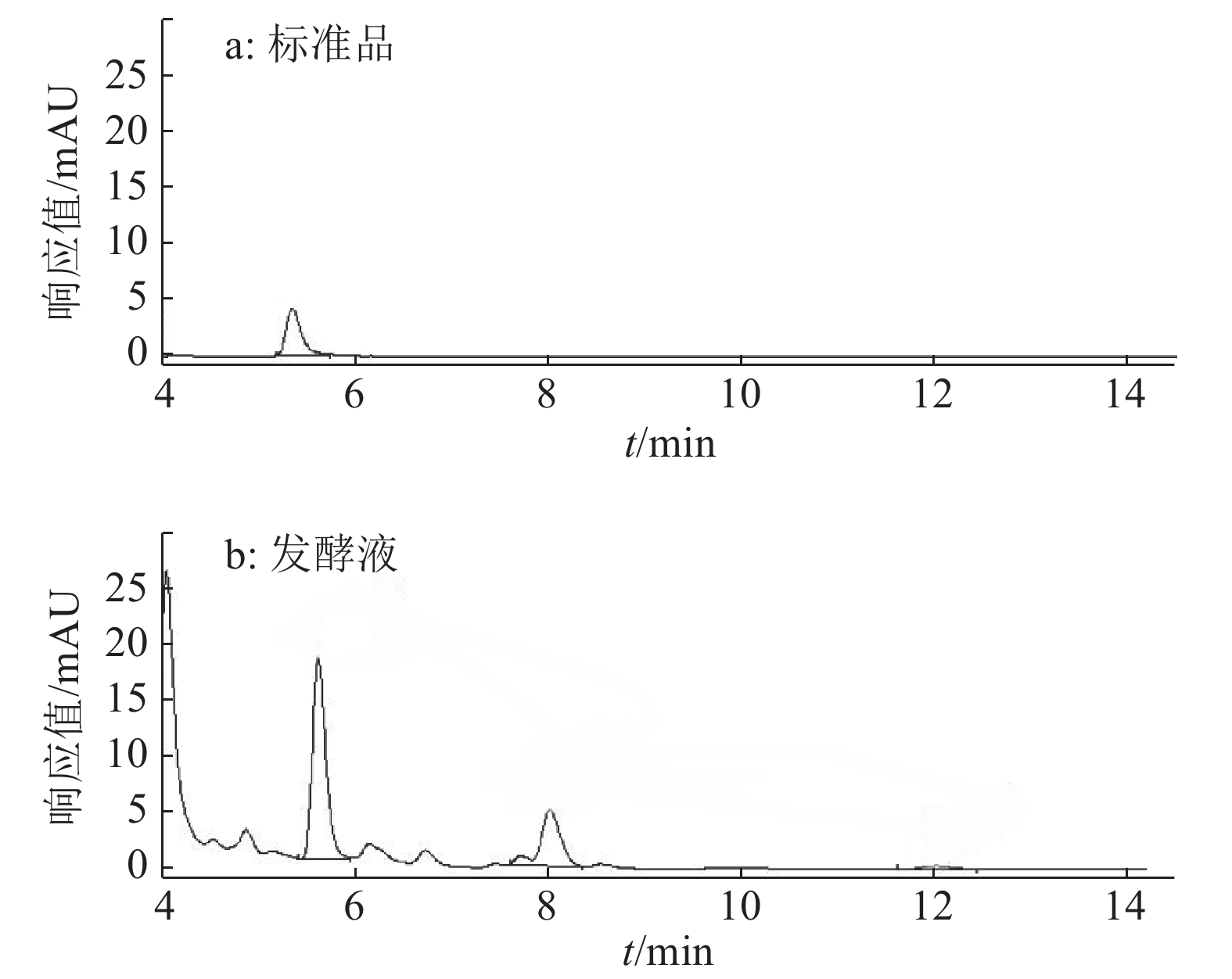
![]()
图 1 绿僵菌素A标准品和发酵液HPLC色谱图
Figure 1. HPLC chromatogram of destruxin A standard substance and fermentation broth
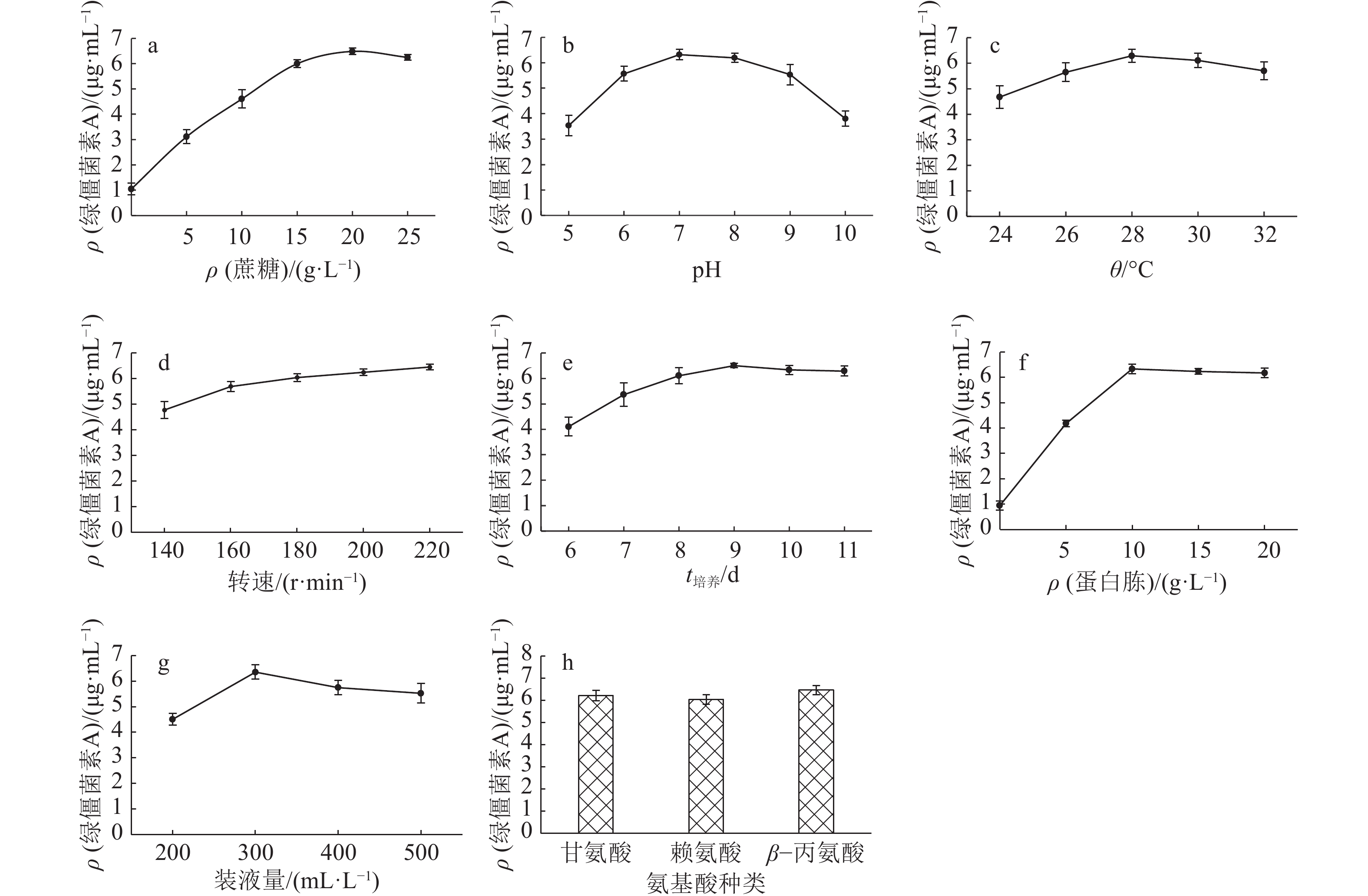
![]()
图 2 各因素对绿僵菌素A产量的影响
Figure 2. Effects of different factors on the production of destruxin A
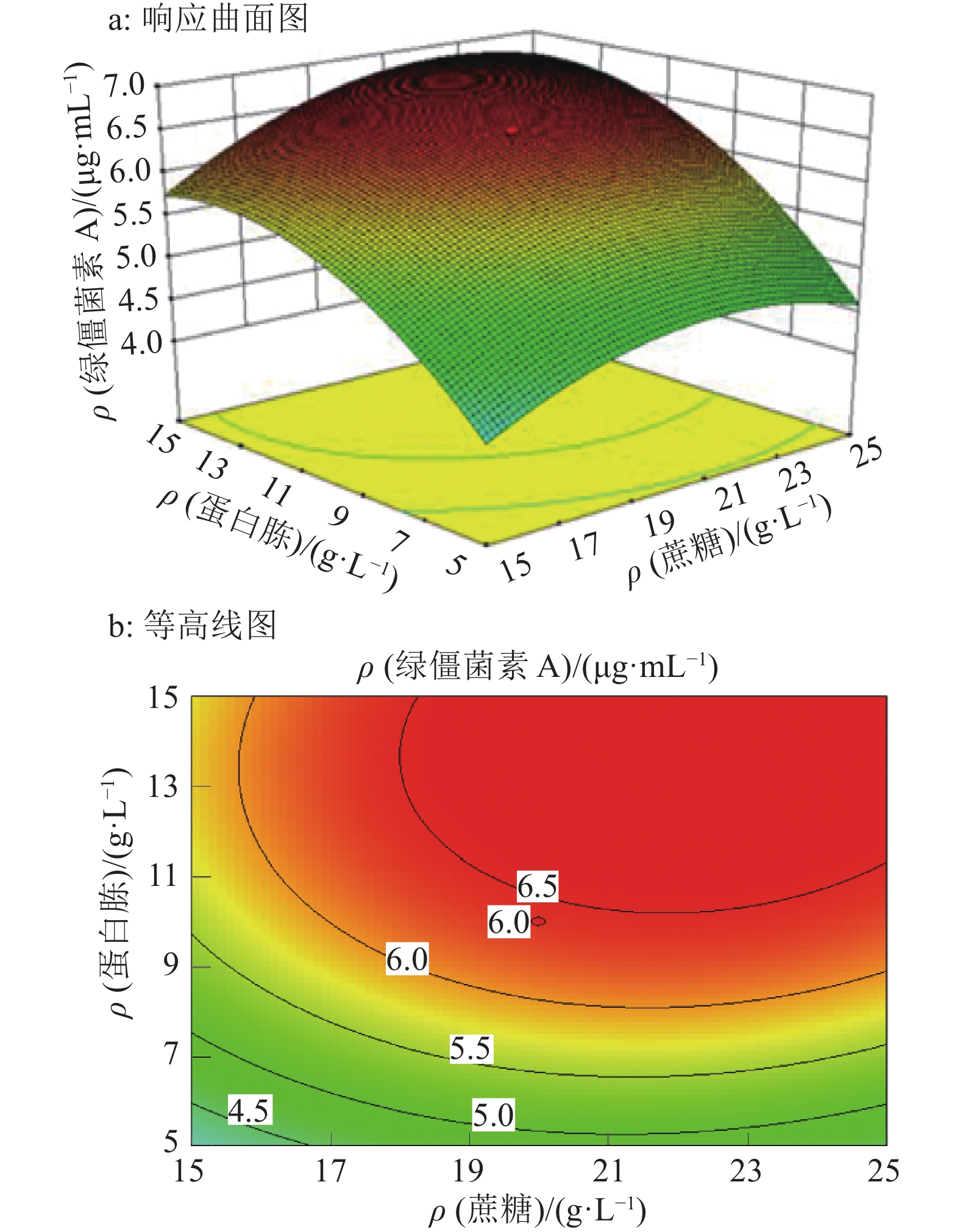
![]()
图 3 蔗糖与蛋白胨交互影响的响应曲面和等高线图
Figure 3. Response surface and contour of interaction between sucrose and peptone contents
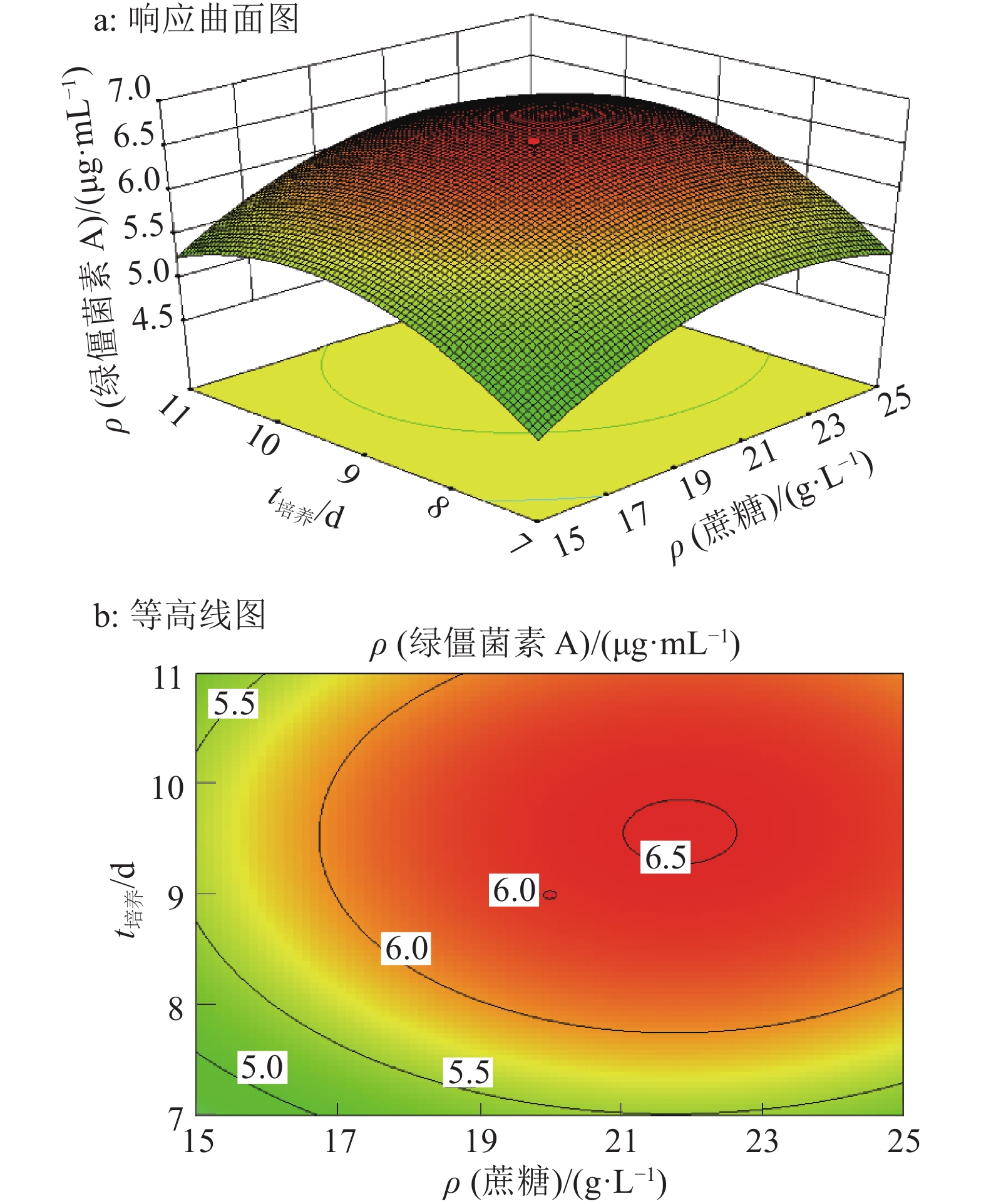
![]()
图 4 蔗糖与培养时间交互影响的响应曲面和等高线图
Figure 4. Response surface and contour of interaction between sucrose content and fermentation time
![]()
图 5 蛋白胨与培养时间交互影响的响应曲面和等高线图
Figure 5. Response surface and contour of interaction between peptone content and fermentation time
表 1 Plackett-Burman试验设计因素水平表
Table 1 Factors and levels of Plackett-Burman design
水平 因素 ρ(蔗糖)/
(g·L–1)pH θ/℃ 转速/
(r·min–1)t培养/d ρ(蛋白胨)/
(g·L–1)装液量/
(mL·L–1)ρ(β–丙氨酸)/
(g·L–1)–1 5 5 24 140 6 5 200 1 1 25 10 32 220 11 20 500 2  下载: 导出CSV
下载: 导出CSV
表 2 中心组合试验设计因素水平表
Table 2 Factors and levels of central composite design
水平 因素 ρ(蔗糖)/(g·L–1) ρ(蛋白胨)/(g·L–1) t培养/d –1 15 5 7 0 20 10 9 1 25 15 11
下载: 导出CSV
表 3 Plackett-Burman试验设计及结果
Table 3 Plackett-Burman design and results
试验号 因素及水平 ρ(绿僵菌素A)/(μg·mL–1) 蔗糖质量浓度 pH 温度 转速 培养时间 蛋白胨质量浓度 装液量 β–丙氨酸质量浓度 实际值 预测值 1 1 –1 1 1 –1 1 1 1 5.26 4.92 2 –1 1 –1 1 1 –1 1 1 3.54 3.08 3 –1 –1 –1 –1 –1 –1 –1 –1 2.26 1.92 4 1 –1 1 1 1 –1 –1 –1 4.93 4.92 5 1 1 –1 1 1 1 –1 –1 6.55 6.56 6 –1 –1 –1 1 –1 1 1 –1 2.99 3.33 7 1 –1 –1 –1 1 –1 1 1 3.81 4.27 8 –1 –1 1 –1 1 1 –1 1 4.91 4.80 9 –1 1 1 –1 1 1 1 –1 2.94 3.05 10 –1 1 1 1 –1 –1 –1 1 1.88 2.34 11 1 1 –1 –1 –1 1 –1 1 5.17 5.16 12 1 1 1 –1 –1 –1 1 –1 1.89 1.78
下载: 导出CSV
表 4 Plackett-Burman试验的方差分析
Table 4 Variance analysis of Plackett-Burman design
因素 效应 F P1) 贡献值/% 重要性 蔗糖质量浓度 1.52 20.56 0.020 1* 27.30 2 pH –0.37 1.19 0.354 5 1.58 8 温度 –0.42 1.57 0.299 2 2.08 7 转速 0.70 4.33 0.129 0 5.74 5 培养时间 1.21 13.01 0.036 6* 17.27 3 蛋白胨质量浓度 1.59 22.51 0.017 8* 29.88 1 装液量 –0.88 6.91 0.078 4 9.17 4 β–丙氨酸质量浓度 0.50 2.25 0.230 2 2.99 6 1)“*”表示该因素的影响达到显著水平(P<0.05,t 检验)
下载: 导出CSV
表 5 响应面中心组合设计及结果
Table 5 Central composite design and results
试验号 因素及水平 ρ(毒素A)/
( μg·mL–1)蔗糖质量
浓度(A)蛋白胨质量
浓度(B)培养时
间(C)实际值 预测值 1 1 –1 –1 3.52 3.60 2 1 –1 1 4.43 4.34 3 –1 1 –1 4.57 4.80 4 –1.682 0 0 4.59 4.40 5 –1 1 1 5.39 5.45 6 0 0 0 6.55 6.40 7 –1 –1 –1 3.30 3.18 8 0 –1.682 0 3.13 3.12 9 0 0 0 6.54 6.40 10 0 0 0 6.35 6.40 11 1 1 1 6.20 6.46 12 0 0 1.682 5.45 5.23 13 0 0 0 6.31 6.40 14 1.682 0 0 5.62 5.60 15 1 1 –1 5.84 5.73 16 0 1.682 0 6.46 6.26 17 0 0 0 6.26 6.40 18 0 0 0 6.34 6.40 19 0 0 –1.682 4.04 3.85 20 –1 –1 1 3.59 4.06
下载: 导出CSV
表 6 响应面模型方差分析1)
Table 6 Variance analysis of response surface model
来源 平方和 自由度 均方 F P 模型 27.44 9 3.05 70.20 <0.000 1** A 1.74 1 1.74 40.02 <0.000 1** B 11.92 1 11.92 274.51 <0.000 1** C 1.65 1 1.65 38.06 0.000 1** AB 0.13 1 0.13 2.99 0.114 2 AC 3.20×10–3 1 3.20×10–3 0.07 0.791 6 BC 5.00×10–5 1 5.00×10–5 1.15×10–3 0.973 6 A2 3.52 1 3.52 80.96 <0.000 1** B2 5.25 1 5.25 120.87 <0.000 1** C2 5.56 1 5.56 128.06 <0.000 1** 残差 0.43 10 0.04 失拟项 0.36 5 0.07 4.75 0.056 1 纯误差 0.08 5 0.02 总和 27.87 19 1)A、B、C分别为蔗糖质量浓度、蛋白胨质量浓度和培养时间;“**”表示达极显著水平(P<0.001,t检验);R2=0.984,R2adj=0.970 4
下载: 导出CSV
-
[1] ARROYO N, DIANA D M J, GARRIDO I, et al. Analytical strategy for determination of known and unknown destruxins using hybrid quadrupole-orbitrap high-resolution mass spectrometry[J]. Anal Bioanal Chem, 2017, 409(13): 1-11.
[2] RCCAVINDRAN K, AKUTSE K S, SIVARAMAKRISHNAN S, et al. Determination and characterization of destruxin production in Metarhizium anisopliae Tk6 and formulations for Aedes aegypti mosquitoes control at the field level[J]. Toxicon, 2016, 120: 89-96.
[3] RIOSMORENO A, CARPIO A, GARRIDO I, et al. Production of destruxins by Metarhizium strains under different stress conditions and their detection by using UHPLC-MS/MS[J]. Biocontrol Sci Techn, 2016, 26(9): 1-25.
[4] LOZANO M D, GARRIDO I, LAFONT F, et al. Insecticidal activity of a destruxin-containing extract of Metarhizium brunneum against Ceratitis capitata (Diptera: Tephritidae)[J]. J Econ Entomol, 2015, 108(2): 462-472.
[5] KERSHAW M J, MOORHOUSE E R, BATEMAN R, et al. The role of destruxins in the pathogenicity of Metarhizium anisopliae for three species of insect[J]. J Invertebr Pathol, 1999, 74(3): 213.
[6] DUMAS C, ROBERT P, PAIS M, et al. Insecticidal and cytotoxic effects of natural and hemisynthetic destruxins[J]. Comp Biochem Phys C, 1994, 108(2): 195-203.
[7] 蔡守平. 绿僵菌MaZPTR-01菌株固体发酵条件筛选研究[J]. 西南林业大学学报, 2016, 36(5): 100-105. [8] 许天委, 张世清, 黄俊生. 金龟子绿僵菌的液固双相发酵研究[J]. 河南农业科学, 2013, 42(2): 93-97. [9] 胡琼波, 任顺祥. 绿僵菌素的研究进展[J]. 中国生物防治学报, 2004, 20(4): 234-242. [10] 刘志祥, 曾超珍. 响应面法在发酵培养基优化中的应用[J]. 北方园艺, 2009(2): 127-129. [11] RUQAYYAH T, JAMAL P, ALAM M, et al. Application of response surface methodology for protein enrichment of cassava peel as animal feed by the white-rot fungus Panustigrinus M609RQY[J]. Food Hydrocolloid, 2014, 42(2): 298-303.
[12] TRUPKIN S, LEVIN L, FORCHIASSIN F, et al. Optimization of a culture medium for ligninolytic enzyme production and synthetic dye decolorization using response surface methodology[J]. J Ind Microbio Biot, 2003, 30(12): 682-690.
[13] 李莉, 张赛, 何强, 等. 响应面法在试验设计与优化中的应用[J]. 实验室研究与探索, 2015, 34(8): 41-45. [14] 卢艳阳. 绿僵菌粗毒素的提取、分离和结构鉴定及对几种重要害虫的毒性测定[D]. 扬州: 扬州大学, 2007. [15] HU Q, REN S, WU J, et al. Investigation of destruxin A and B from 80 Metarhizium strains in China, and the optimization of cultural conditions for the strain MaQ10[J]. Toxicon, 2006, 48(5): 491-498.
[16] ITOH N, OKOCHI M, TAGAMI S, et al. Destruxin E decreases beta-amyloid generation by reducing colocalization of beta-amyloid-cleaving enzyme 1 and beta-amyloid protein precursor[J]. Neurodegener Dis, 2009, 6(5/6): 230-239.
[17] KOUVELIS V N, WANG C, SKROBEK A, et al. Assessing the cytotoxic and mutagenic effects of secondary metabolites produced by several fungal biological control agents with the Ames assay and the VITOTOX (R) test[J]. Mutat Res-Gen Tox En, 2011, 722(1): 1-6.
[18] WU C, CHEN T, LIU B, et al. Destruxin B isolated from entomopathogenic fungus Metarhizium anisopliae induces apoptosis via a Bcl-2 family-dependent mitochondrial pathway in human nonsmall cell lung cancer cells[J]. Evid-Based Compl Alt, 2013, 2013: 1-11.
[19] LIU B, TZENG Y. Development and applications of destruxins: A review[J]. Biotechnol Adv, 2012, 30(6): 1242-1254.
[20] 张婧迪, 蔡明美, 刘志诚, 等. 响应面设计优化绿僵菌固体发酵条件[J]. 微生物学通报, 2016, 43(9): 2072-2078. [21] 张棋, 胡永红, 杨文革, 等. 金龟子绿僵菌发酵培养基响应面优化[J]. 江苏农业科学, 2016, 44(7): 173-176.